ZFS – présentation
Posted by Daniel on 01 Sep 2008 at 09:00 | Tagged as: solaris
ZFS est un nouveau genre de système de fichiers, intègrant également des fonctions traditionnellement dévolues aux outils de gestion de volumes. Le projet a été initié chez Sun en 2000, sous la houlette de Jeff Bonwick, pour remplacer un UFS qui, il faut le reconnaître, vieillissait plutôt mal. L'utilisation massive de Veritas Volume Manager (aka Symantec Storage Foundation) en entreprise, voire même de Solaris Volume Manager, indique bien que ce système de fichiers ne répondait plus vraiment aux besoins des utilisateurs.
Voyons donc un peu de quoi il retourne, et notamment quelles innovations ZFS apporte.
Pool et dataset
Les pools
Le concept fondamental de ZFS et la notion de pool. Il s'agit d'un espace de stockage qui sera vu comme un seul ensemble, très similaire en cela à un disk group (VxVM) ou volume group (LVM), à ceci près qu'il peut agréger non seulement des disques, mais également des partitions ou même des fichiers.
Les datasets
Le dataset est l'unité logique de base de ZFS, là encore très similaire aux volumes (VxVM) ou logical volumes (LVM). Au sein d'un pool donné, les datasets peuvent être structurés hiérarchiquement, c'est-à-dire qu'un dataset peut être rattaché non pas à la racine du pool, mais à un dataset déjà existant. Ce mécanisme permet à tous les descendants d'un dataset d'hériter des propriétés de ses parents.
Un dataset peut bien entendu héberger une structure de fichiers ZFS, mais il peut également être utilisé en raw device, par exemple pour en faire un espace de swap.
Gestion de la volumétrie
Jusque-là, on pourrait se dire qu'il n'y a rien de bien nouveau, et qu'il ne s'agit que d'un outil de gestion de volumes de plus. Pourtant, il y a déjà une différence majeure : au sein d'un pool, l'espace est partagé entre tous les datasets, il n'y a pas besoin de définir une taille à la création du dataset, il occupe l'espace qui lui est nécessaire, bien entendu dans la limite des stocks disponibles (la taille du pool au maximum, ou moins si des quotas ont été mis en place). Fini les extensions de filesystems! Terminé les problèmes de provisionnement d'espace et le gâchis qui peut en résulter!
Fiabilité et performances
Les avancées de ZFS ne se limitent pas à la gestion de l'espace disque, on y retrouve également plusieurs apports notables dans le domaine de la fiabilité.
Des données toujours cohérentes
ZFS garantit que les données sur le disque seront toujours cohérentes, même en cas de crash du système. Il se repose pour cela sur un mécanisme appelé copy on write, ou simplement COW. Il s'agit d'utiliser un modèle transactionnel pour toute écriture sur le disque.
En pratique, quand ZFS doit écrire dans un fichier, par exemple, il n'écrase pas les données existantes, mais utilise de nouveaux blocs. Une fois que les nouvelles données sont écrites, les blocs indirects associés sont mis à jour (ceux-ci ne contiennent pas de données à proprement parler, mais des pointeurs vers d'autres blocs), et on remonte ainsi la hiérarchie jusqu'à l'uberblock.
Ce dernier est l'élément contenant les informations qui permettent d'accéder à l'ensemble des données du pool, conceptuellement similaire au superblock d'UFS. L'opération de mise à jour de l'uberblock est atomique, autrement dit, soit elle a lieu complètement, soit elle n'a pas lieu du tout. Si elle a lieu complètement, ce sont les nouvelles données qui sont référencées et cohérentes. Si elle n'a pas lieu du tout, ce sont les anciens blocs qui sont toujours référencés, et, bien que les nouvelles données aient été écrites sur le disque (sans écraser les anciennes), tout se passe comme si cette écriture n'avait pas eu lieu.
Niveaux de réplication
ZFS propose trois modes de réplication des données :
- Pas de réplication : l'ensemble des devices définis dans le pool sont simplement concaténés
- Miroir : dis-moi qui est la plus belle (oui, à part ça, c'est exactement ce que vous pensez que c'est)
- Raid-Z : une alternative au Raid-5, basée sur le même concept (à savoir, l'utilisation d'un bit de parité par XOR), mais utilisant une profondeur de stripe variable, et conçu pour éviter le fameux "trou" du Raid-5 (le Raid-5 write hole)
- Chaque bloc Raid-Z est traité comme un stripe complet, quelle que soit la taille du bloc. Ainsi, toute écriture de bloc est traitée comme un full-stripe write, d'où un gain de performance (pas de ead-modify-write)
- La gestion transactionnelle des opérations d'écriture (COW) permet de garantir qu'un full-stripe write aura lieu complètement ou pas du tout, puisque tout se passe au sein du même pool
Le Raid-Z
Le Raid-Z est un concept suffisamment complexe pour que l'on s'y intéresse d'un peu plus près. Avant toute chose, rappelons la principale faiblesse du RAID 5. Lors d'une opération d'écriture, on va devoir écrire des données sur chaque disque (hors parité), calculer la parité, et écrire cette parité. Etant donné qu'on s'adresse à des devices différents, il est impossible de rendre l'ensemble de l'opération atomique. Si le système se plante au milieu d'une telle opération, on peut donc se retrouver avec une parité incohérente, et aucun moyen de savoir quelles données ont pu être écrites ou non. Il existe un second problème, lié à ce que l'on appelle les partial-stripe writes. Il s'agit de la situation où on n'écrase pas la totalité d'un stripe, mais seule une partie doit être mise à jour. Dans ce cas, il faut au préalable lire les données qui ne seront pas écrasées, puisqu'elles seront nécessaires pour recalculer la parité. On parle parfois de read-modify-write, et l'impact sur les performances est assez désastreux. Le Raid-Z corrige ces deux problèmes avec une approche originale, en faisant un full-stripe write à chaque fois. Mais comment peut-on décider que chaque bloc, indépendamment de sa localisation physique, est un stripe complet? En fait, ça n'est possible que parce que ZFS est à la fois un système de fichiers et un outil de gestion de volumes, conscient aussi bien de la structure logique que de l'architecture physique des devices sous-jacents.Self-healing : checksum et scrubbing
Un des grands points forts de ZFS est la fonctionnalité appelée self-healing. Quel que soit le niveau de redondance, chaque bloc dispose d'un checksum de 256 bits. La fonction dite de scrubbing, utilisable à chaud sur un pool actif, va vérifier que chaque bloc est intact. En cas d'altération des données, et s'il existe une copie de ces données (cas du miroir ou du raid-Z), ZFS restaurera tout seul le bloc concerné. Le scrubbing peut être lancé manuellement sur l'ensemble d'un pool, mais, surtout, la vérification du checksum se fait lors de chaque lecture d'un bloc, garantissant un accès à des données valides.Le pipeline d'I/O
Enfin, pour ce qui est des performances, ZFS utilise un pipeline, reprenant un certain nombre de concepts utilisés dans les processeurs. Cela est censé lui permettre de supporter des charges I/O considérables. Je n'ai pas fait de comparaisons moi-mêmes, mais les résultats des premiers tests de performance, datant de 2005 et présentés dans le blog de Roch Bourbonnais, sont assez parlants : sur 12 scénarios de test, ZFS s'est montré 3 fois plus performant qu'UFS (couplé à SVM) dans 10 cas, et sensiblement équivalent à UFS pour les 2 derniers.Fonctions avancées
Quotas et réservations
ZFS permet d'appliquer très simplement des quotas au niveau de chaque dataset, et de les faire évoluer dynamiquement selon les besoins. Un quota peut être placé indépendamment de l'espace total disponible dans le pool : on peut mettre un quota de 15 Go sur un dataset appartenant à un pool de 10 Go. Bien entendu, dans ce cas précis, ça ne sert à rien, mais si un jour le pool dépasse 15 Go, le quota s'appliquera. A l'inverse, une réservation permet de garantir un espace minimum pour un dataset. Ainsi, si on donne à un dataset une réservation de 10 Go mais qu'il ne contient que 6 Go de données, le système considèrera que les 10 Go sont effectivement occupés par le dataset. Les 4 Go supplémentaires ne pourront donc pas être consommés par d'autres datasets du même pool, et resteront réservés à notre dataset.Clones et snapshots
Le snapshot est une fonctionnalité qui existe depuis un certain temps dans les baies de stockage : il s'agit de figer un dataset à un instant t, c'est-à-dire d'en prendre une photo. Ce snapshot n'occupe initialement aucun espace. En revanche, au fur et à mesure que les données du dataset concerné vont évoluer, les données d'origine seront copiées dans le snapshot. Ceci permettra de reconstituer l'intégralité des données présentes dans le dataset à l'instant t en combinant les données qui n'ont pas été écrasées (toujours présentes dans le dataset) et les données d'origine qui ont depuis été écrasées (que l'on retrouvera dans le snapshot).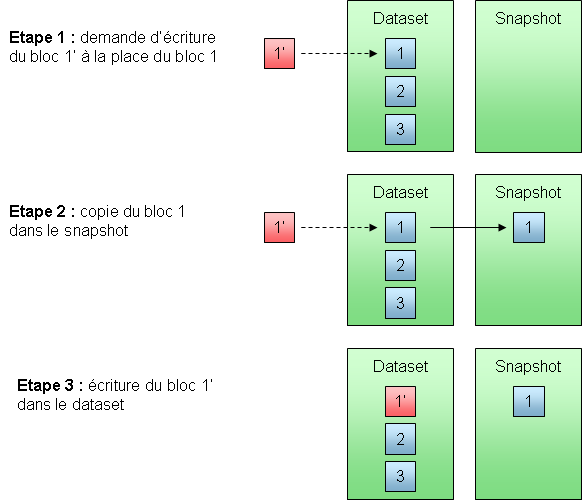
- Le clone est quasiment identique au snapshot, à ceci près que l'on peut écrire dans un clone. Cela permet de maintenir deux jeux de données quasiment identiques sans dupliquer intégralement les données.
 Flux RSS 2.0
Flux RSS 2.0